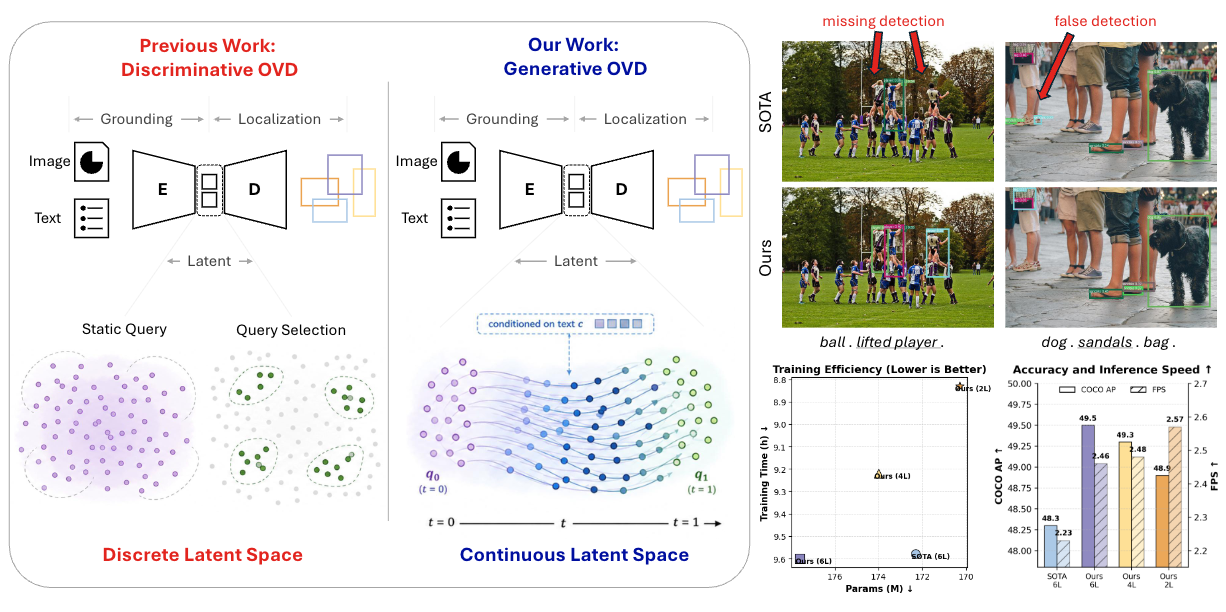
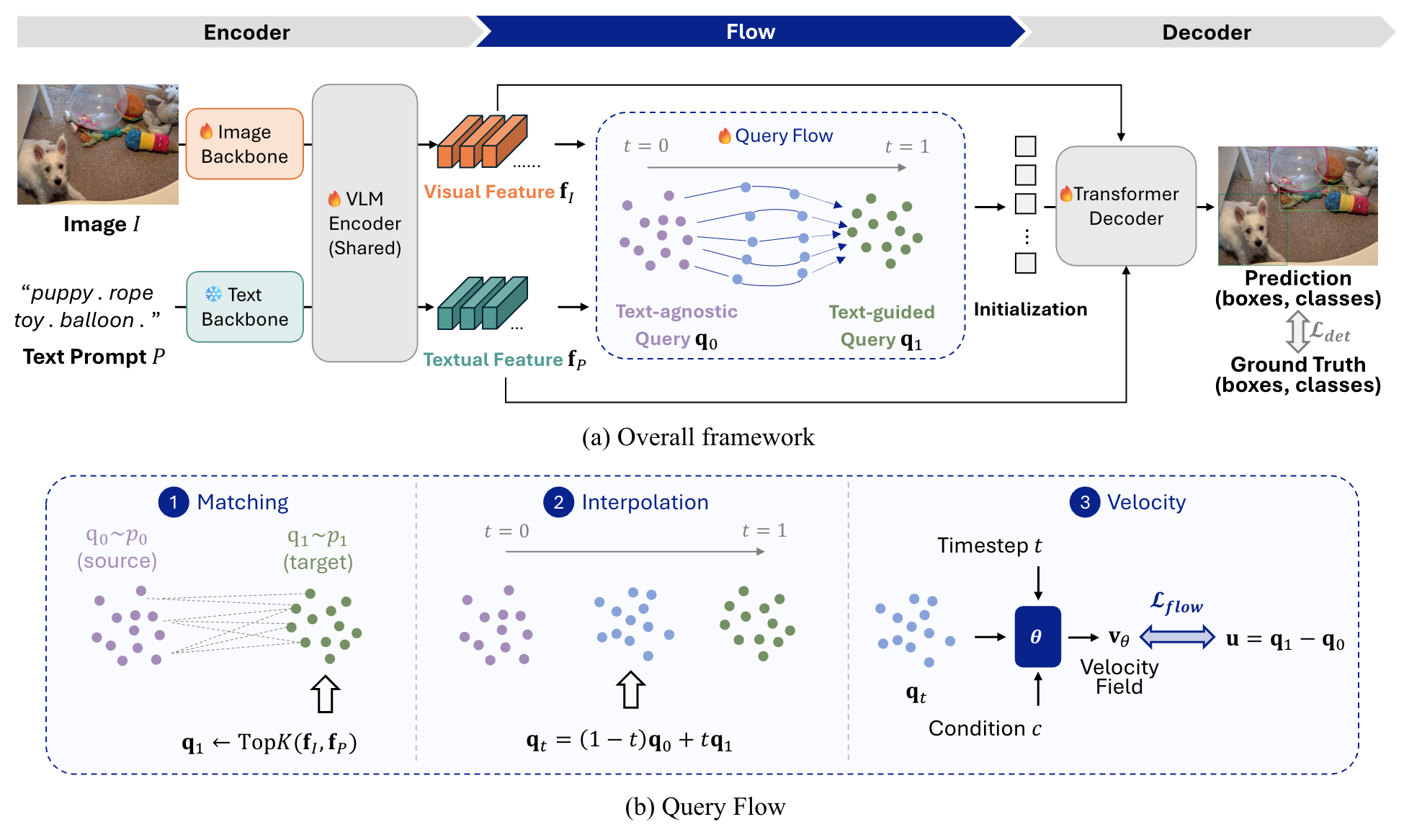
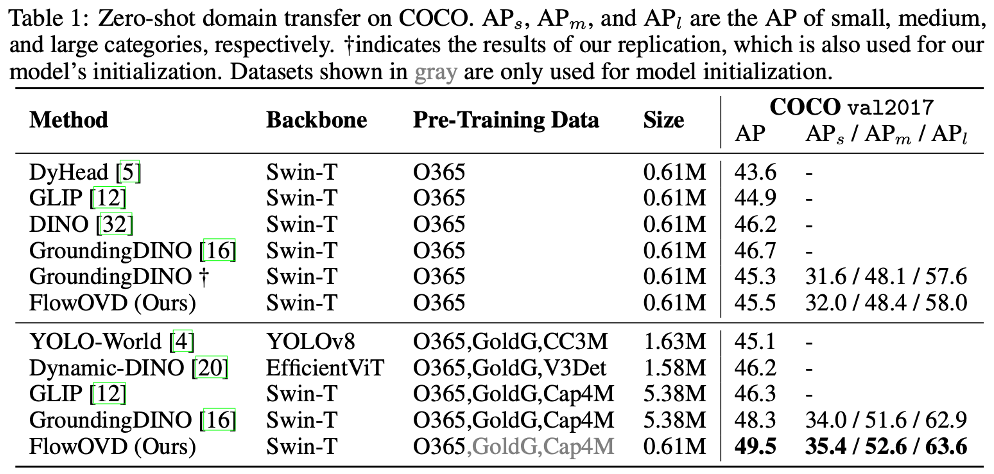
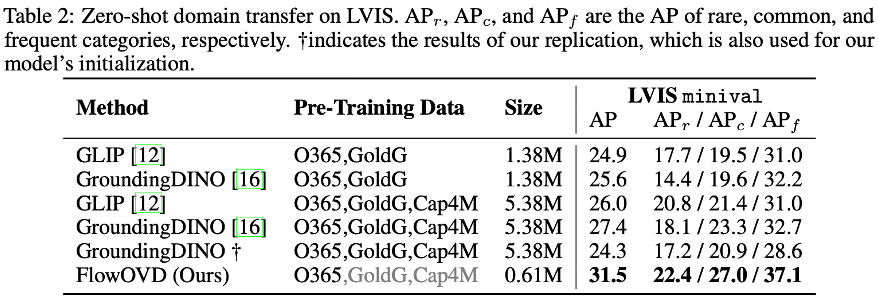
Open-vocabulary object detection (OVD) has achieved remarkable progress through large-scale vision-language pre-training. Existing methods, however, typically formulate OVD as a discriminative prediction problem, where decoder queries are either static or initialized from encoder features, thus limiting their diversity and flexibility. In this paper, we introduce a generative perspective by modeling decoder query generation as a continuous transport process in latent space. We propose FlowOVD, a text-conditioned query generation framework based on rectified flow that progressively transforms text-agnostic queries into text-guided queries. By introducing continuous latent query dynamics into a vision-language model (VLM) based detector, our method avoids heuristic discrete query construction and enables more expressive semantic alignment for open-vocabulary detection. Without requiring additional training data, FlowOVD achieves 49.5 AP on COCO and 31.5 AP on LVIS, outperforming GroundingDINO by +1.2 AP (+2.5 %) and +4.1 AP (+15.0 %), respectively. The larger gain on the challenging long-tailed LVIS benchmark further highlights the effectiveness of continuous query generation for open-vocabulary generalization.