ABSTRACT: We propose a test-time adaptation for 6D object pose tracking that learns to adapt a pre-trained model to track the 6D pose of novel objects. We consider the problem of 6D object pose tracking as a 3D keypoint detection and matching task and present a model that extracts 3D keypoints. Given an RGB-D image and the mask of a target object for each frame, the proposed model consists of the self- and cross-attention modules to produce the features that aggregate the information within and across frames, respectively. By using the keypoints detected from the features for each frame, we estimate the pose changes between two consecutive frames, which enables 6D pose tracking when the 6D pose of a target object in the initial frame is given. Our model is first trained in a source domain, a category-level tracking dataset where the ground truth 6D pose of the object is available. To deploy this pre-trained model to track novel objects, we present a test-time adaptation strategy that trains the model to adapt to the target novel object by self-supervised learning. Given an RGB-D video sequence of the novel object, the proposed self-supervised losses encourage the model to estimate the 6D pose changes that can keep the photometric and geometric consistency of the object. We validate our method on the NOCS-REAL275 dataset and our collected dataset, and the results show the advantages of tracking novel objects.
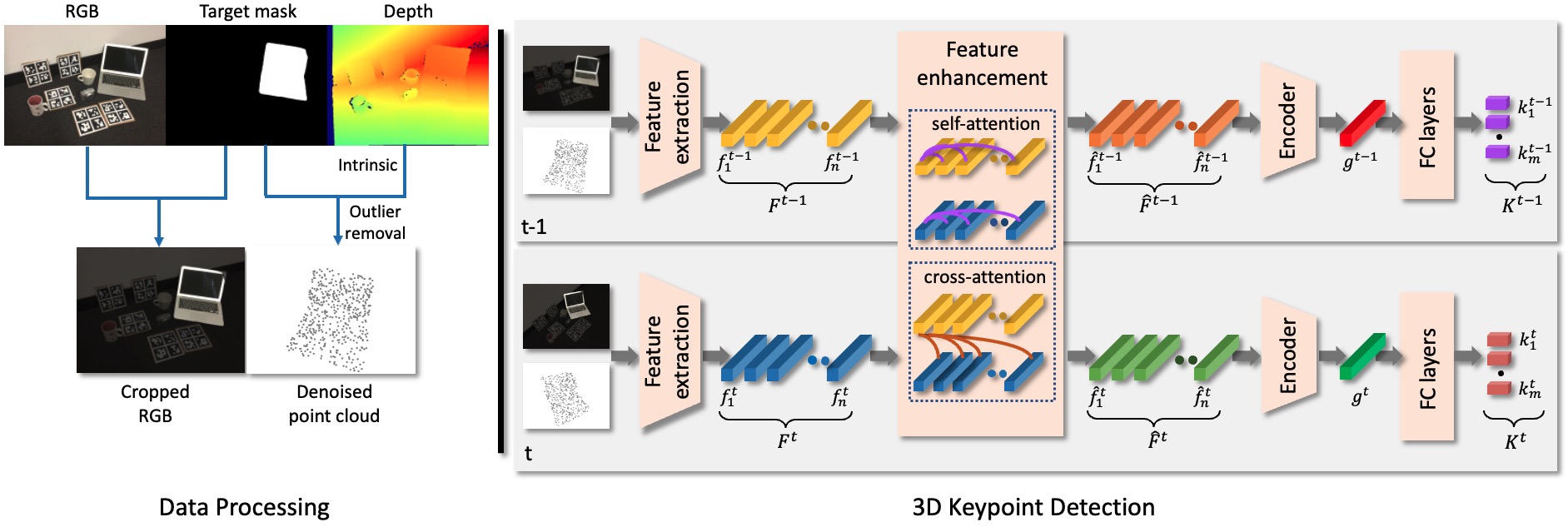
The proposed framework for keypoints detection. In the data processing, we first crop RGB and depth images using the object mask and lift cropped depth to the point cloud. In the 3D keypoint detection, we extract the fused appearance and geometric features from the cropped RGB and the point cloud of the target object. We then utilise self-attention and cross-attention to aggregate intra-frame and inter-frame features. The output points features are then processed through an encoder to generate a global feature that is used as input for a fully connected (FC) layer to estimate the 3D keypoints.
Overview
Stage 1. The model is first pre-trained on the source domain for category-level 6D pose tracking by minimising the supervised loss.
Stage 2. We adapt the pre-trained parameters to novel objects using our self-supervised losses.
| Stage 1 Pre-training | Stage 2 Adaptation | ||
| NOCS-REAL275 dataset. | Novel object data collection. The robotic arm follows our pre-desinged trajector, while RGB-D camera recording the scene information. |
Tracking results
Please select one pre-trained model
| Categories | |||
| bottle |
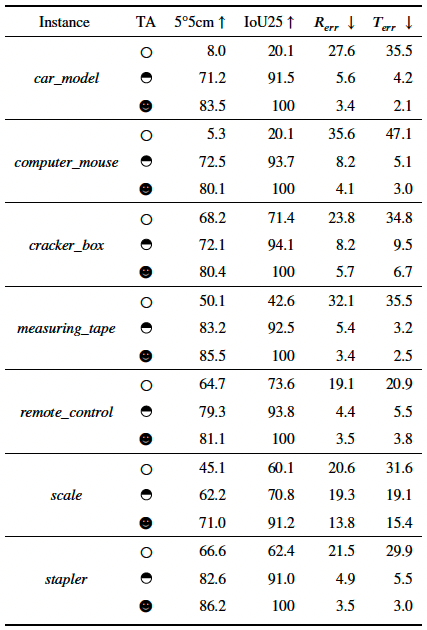
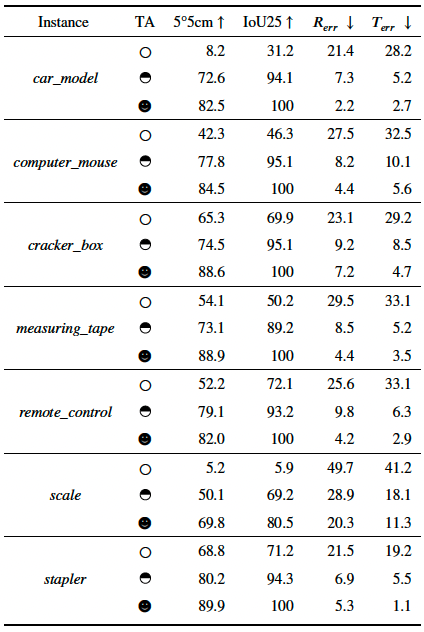
Adaptation results on our collected dataset. We present the three different adaptation settings: without TA, using the 50% sequence for training the rest for testing and using all the sequence for training and testing, which are denoted by a circle, a half circle and a full circle, respectively.
Red bounding box: Ground truth
Green bounding box: With setting of full circle
Black bounding box: With setting of circle
|
|
|---|
| Categories | |||
| bowl |
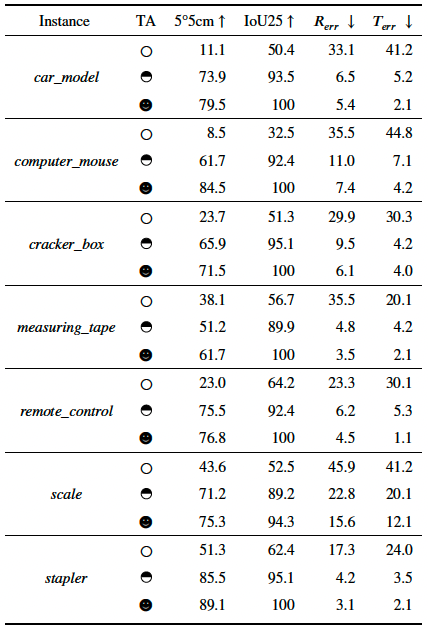
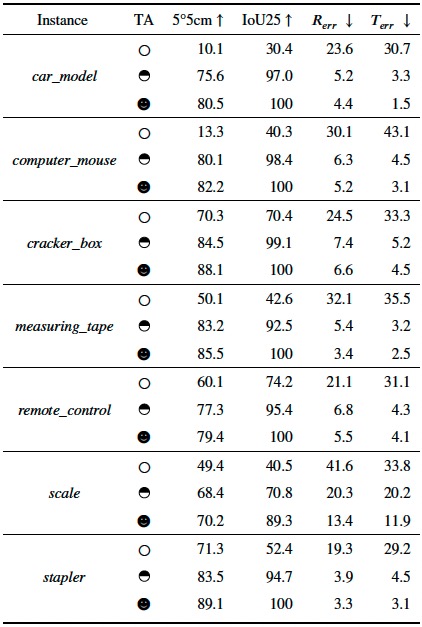
Adaptation results on our collected dataset. We present the three different adaptation settings: without TA, using the 50% sequence for training the rest for testing and using all the sequence for training and testing, which are denoted by a circle, a half circle and a full circle, respectively.
Red bounding box: Ground truth
Green bounding box: With setting of full circle
Black bounding box: With setting of circle
|
|
|---|
| Categories | |||
| camera |
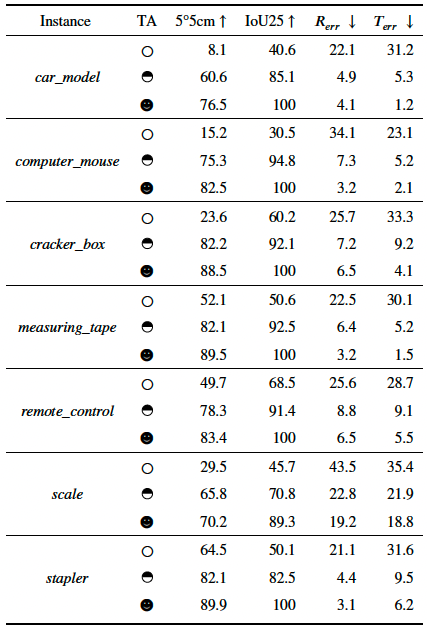
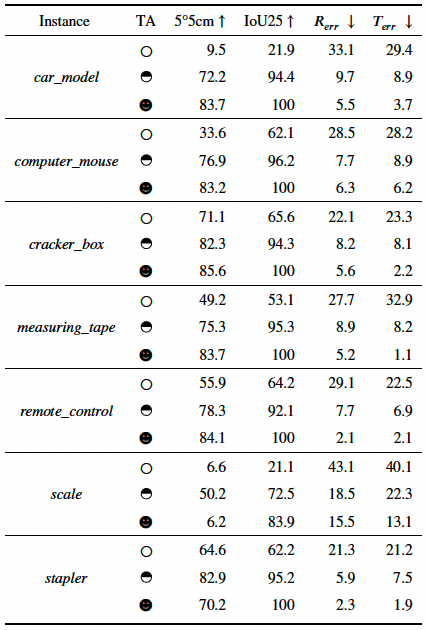
Adaptation results on our collected dataset. We present the three different adaptation settings: without TA, using the 50% sequence for training the rest for testing and using all the sequence for training and testing, which are denoted by a circle, a half circle and a full circle, respectively.
Red bounding box: Ground truth
Green bounding box: With setting of full circle
Black bounding box: With setting of circle
|
|
|---|
| Categories | |||
| can |
Adaptation results on our collected dataset. We present the three different adaptation settings: without TA, using the 50% sequence for training the rest for testing and using all the sequence for training and testing, which are denoted by a circle, a half circle and a full circle, respectively.
Red bounding box: Ground truth
Green bounding box: With setting of full circle
Black bounding box: With setting of circle
|
|
|---|
| Categories | |||
| laptop |
Adaptation results on our collected dataset. We present the three different adaptation settings: without TA, using the 50% sequence for training the rest for testing and using all the sequence for training and testing, which are denoted by a circle, a half circle and a full circle, respectively.
Red bounding box: Ground truth
Green bounding box: With setting of full circle
Black bounding box: With setting of circle
|
|
|---|
| Categories | |||
| mug |
Adaptation results on our collected dataset. We present the three different adaptation settings: without TA, using the 50% sequence for training the rest for testing and using all the sequence for training and testing, which are denoted by a circle, a half circle and a full circle, respectively.
Red bounding box: Ground truth
Green bounding box: With setting of full circle
Black bounding box: With setting of circle
|
|
|---|
Limitations
We captured three videos to evaluate our model performance under different conditions: occlusions, new trajectory and lighting changes.
OcclusionsNew trajectory
Lighting changes
It comprises two segments: normal lighting and low-light condition. We train model with normal images and test with low-light images.
| The lighting changes video | Testing results |
Contacts
If you have any further enquiries, question, or comments, please contact long.tian@qmul.ac.uk.